

「ChatGPTにコードを書かせたのに、エラーだらけで動かない…」
「AIが直してくれた修正版を貼ったら、別のエラーが出て無限ループ…」
「副業で納期があるのに、デバッグで夜が溶けていく…」
結論から言うと、AIが出すコードは便利ですが、“不正確さが前提”です。だからこそ、AIプログラミングで稼げるかどうかの分かれ目は「一発で正解を当てる運」ではなく、壊れた箇所を最短で特定して直す“検証の型(SOP)”を持っているかどうかで決まります。
この記事では、AIプログラミング副業でハマりやすい落とし穴を整理しつつ、効率的なデバッグ・検証フロー(SOP)と、コピペで使える指示テンプレ、納品前チェックリストまでを手順書としてまとめます。
※注意:本記事は一般的な開発ノウハウです。案件の契約条件(品質基準・セキュリティ要件・利用OSSのライセンス等)によっては対応が変わります。最終判断はクライアントの要件・規約に従ってください。
- AIコードが動かない原因は主に「環境差」「前提のズレ」「存在しないAPI(幻覚)」
- 最短ルートは最小再現(MRE)→切り分け→1点修正→テストで固定
- “聞き方”より重要なのはログ・バージョン・再現手順を渡すこと
- 副業で致命傷になりやすいのは秘密情報の投入と無限修正ループ
なぜChatGPTのコードは動かないのか:落とし穴は主に7つ
落とし穴1:環境が違う(バージョン、OS、権限、実行方法)
AIはあなたのローカル環境を知りません。Python 3.10と3.12、Node 16と20、WindowsとmacOSで挙動が変わるのは普通です。「自分の環境では動かない」問題の多くは、バージョン差・実行方法の差で説明がつきます。
落とし穴2:依存関係が抜けている(インストール手順・設定ファイルが欠ける)
コード本体は合っていても、requirements.txtやpackage.json、.env、設定ファイルが抜けているパターン。AIは「必要そうなライブラリ」をそれっぽく書きますが、実際には不要だったり、逆に足りなかったりします。
落とし穴3:存在しないAPI/古い書き方を混ぜる(幻覚)
“それっぽい関数名”で存在しないAPIを使ったり、昔のサンプルを混ぜた書き方になったりします。特にフロントエンド、クラウドSDK、AI系ライブラリは更新が速く、幻覚が出やすい領域です。
落とし穴4:仕様が曖昧(入力・出力・例外・境界条件が未定義)
副業案件では「要件がふわっとしている」ことがあります。要件が曖昧だと、AIは“良さそうな解釈”で書きます。結果、動いても期待と違う(=実質バグ)になります。
落とし穴5:データ・I/Oの前提が違う(文字コード、時刻、NULL、桁、実データの汚さ)
CSVの区切り、改行コード、タイムゾーン、空文字の扱い。ここがずれると例外や不正データが出ます。AIコードはサンプルデータで動く前提なので、現実の汚いデータに弱いです。
落とし穴6:例外処理が弱い(エラーを握りつぶす/ログがない)
AIは「try/exceptで囲う」方向に倒しがちですが、ログがないと原因が追えません。動かないときに必要なのは“静かに失敗するコード”ではなく「失敗理由が見えるコード」です。
落とし穴7:セキュリティと秘密情報(APIキー直書き、ログに漏れる、顧客データを貼る)
副業で一番怖いのはこれです。AIはついAPIキーやトークンを直書き例として提示します。秘密情報を含むプロンプトやログを貼ると、漏えい事故の火種になります(クライアント案件では特に)。
AIコードは「叩き台」。検証の型(SOP)がある人が勝つ
AIを“天才エンジニア”として使うと、外れたときに泥沼になります。おすすめは、AIを「高速に叩き台を出す相棒」として扱い、あなたは「検証して合格ラインに上げる編集者」になることです。
まず全体像を、テキスト図解で固定します。
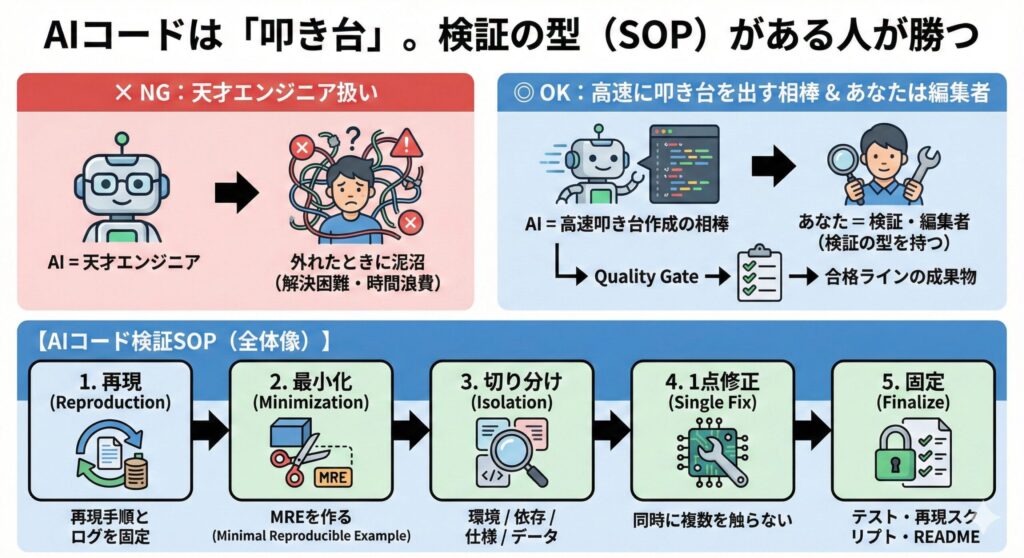
このSOPで回すと、「とりあえずAIに追加質問」→「さらに壊れる」→「また質問」の無限ループから抜けられます。
最短で直す:AIコードのデバッグSOP 5ステップ
ステップ1:まず「再現条件」を固定する(ここがないと永遠に迷う)
最初にやるべきは、AIに追加質問することではなく、あなたの手元で再現性を作ることです。最低限これをメモします。
- 実行コマンド(例:python main.py / npm run dev)
- エラー全文(最初の1行だけでなくスタックトレース)
- バージョン(python –version / node -v)
- 依存(pip freeze / package-lock.json / pnpm-lock.yaml の有無)
- 入力データの条件(例:空行あり、NULLあり、UTF-8、タイムゾーン)
副業では「再現できること」自体が価値です。再現条件が固まると、修正の打率が上がります。
ステップ2:最小再現(MRE)に削る(デバッグは削除ゲー)
動かないコードを全部眺めるのは時間の無駄になりがちです。エラーが起きる最小のコード(MRE)だけ残します。
目安はこんな感じです。
- 1ファイル(可能なら)
- 100行以内
- 外部I/Oなし(API、DB、ファイル読み込みを切る)
- ダミーデータで再現
最小化すると、原因がだいたい以下のどれかに収束します。
- APIが存在しない/使い方が違う
- 型・値・NULLの扱いが違う
- 依存/設定が足りない
ステップ3:原因を4分類で切り分ける(当てずっぽうをやめる)
AIコードのバグ取りは「全部疑う」と負けます。次の4分類で疑う順番を固定します。
- 環境:バージョン、OS、権限、PATH、実行方法
- 依存:インストール、ロックファイル、設定ファイル、ビルド
- 仕様:入力/出力、エッジケース、例外時の期待、受け入れ条件
- データ:実データの汚さ、文字コード、欠損、フォーマット揺れ
おすすめの順番は、環境→依存→仕様→データ。ここが安定すると修正が速くなります。
ステップ4:1回の変更は1点だけ(“同時に直す”は事故の元)
AIが提案した修正をまとめて当てると、どれが効いたのか分からなくなります。副業で大事なのは、最短で“原因”を特定して次に活かすこと。変更は1点→実行→結果確認を徹底します。
もし「修正が当たったか分からない」状態になったら、すぐにステップ2へ戻り、MREをさらに削ります。
ステップ5:直ったらテストで固定する(次の案件でも使える資産化)
AIコードの最大の弱点は再発です。直った瞬間に、簡単でいいのでテストか再現スクリプトを残します。副業で単価が上がる人は、納品物の中に“再現性”を含められる人です。
- ユニットテスト(理想)
- 最小の再現スクリプト(現実的)
- README(環境、実行方法、入力条件)
コピペで使える:AIに“直させる”ための質問テンプレ(デバッグ用)
AIに投げるときは「コード全文」より、再現条件+エラー+最小コードが効きます。以下をコピペして穴埋めしてください。
あなたはシニアエンジニアです。次の条件で発生するエラーを最短で解決してください。
【目的】
- 何を実現したいか:
- 期待する挙動(受け入れ条件):
【実行環境】
- OS:
- 言語/ランタイム:
- 実行コマンド:
- 依存(該当部分):
- ロックファイル有無:
【再現手順】
1)
2)
【エラー全文(省略しない)】
(ここに貼る)
【最小再現コード(MRE)】
(ここに貼る)
【お願い】
- 原因候補を「環境/依存/仕様/データ」で分類して提示
- まず1つだけ修正案を出し、なぜそれが有力か説明
- 修正後に確認すべきチェックコマンドも提示 さらに、AIの“幻覚”を先に潰したいときは、次の一文が効きます。
「存在しないAPIを使っていないか」「バージョン差で挙動が変わらないか」を最優先で疑ってください。 コラム:ChatGPTだけで苦しいなら「AIエディタ」でコンテキスト不足を減らす
「ChatGPTに貼る情報が毎回足りなくて、直しが外れる」タイプの人は、コードベースの文脈(context)を取り込みやすいツールを使うと、修正の命中率が上がることがあります。
たとえばCursorやGitHub Copilotのようなコーディング支援ツールは、エディタ上の文脈を活かしやすいのが強みです。とはいえ、副業・受託では機密情報がどこまで共有されるかが最大の論点になるため、利用前に設定と共有範囲を必ず確認してください。
よくある失敗5選と回避策(副業で地味に致命傷)
失敗1:エラーの一部だけ貼ってAIに丸投げする
起きること:AIが推測で回答し、修正が外れて時間が増えます。
回避策:スタックトレースを省略しない。最小再現コードを作ってから投げる。
失敗2:動くまで“いじり続ける”無限ループに入る
起きること:どこで壊れたか分からなくなり、最終的に作り直しになります。
回避策:変更は1点だけ。Gitでコミットを小さく刻む(戻れる状態を維持)。
失敗3:クライアントのデータやAPIキーをプロンプトに貼る
起きること:守秘義務違反・情報漏えいの火種になります。
回避策:固有名詞はA社/B社、キーはダミー、データはサンプルに置換。ログもマスクして共有する。
失敗4:依存関係を固定せず、環境差で再現しない
起きること:あなたのPCでは動くが、納品先で落ちる。
回避策:依存の固定(lockfile)と、再現手順(README)を残す。
失敗5:動いた瞬間に納品して、翌日バグ報告で炎上する
起きること:境界値や例外ケースで落ちる。信用が落ちやすい。
回避策:最低3ケースのテスト(正常/空/異常)を作って“合格ライン”を定義する。
具体例:AIのコード修正で3時間溶ける人が、30分で原因特定できるようになる
状況:ChatGPTが出したPythonコードで「ModuleNotFoundError」「AttributeError」が連発。修正しても次のエラーが出て、3時間溶ける。
このケースの勝ち筋は、原因の優先順位を固定することです。
- まず環境:Pythonのバージョンと実行コマンドが一致しているか(仮想環境を使っているのに別Pythonで実行していないか)
- 次に依存:pip listで該当パッケージが入っているか。パッケージ名の勘違い(import名とpip名が違う)を疑う
- 次にAPI:AttributeErrorは「古いAPI」「存在しないメソッド」の可能性が高いので、まずメソッド名・引数を確認
そして、ここで重要なのが最小再現(MRE)です。外部APIやファイル読み込みを切り、import→対象関数1つだけ動かす。そうすると「依存がないのか」「APIが存在しないのか」が一発で分かります。
当てずっぽうで直すのではなく、分類で潰すだけで、デバッグ時間は劇的に安定します。
すぐできるチェックリスト:AIコードを“納品できる品質”にする最低ライン
- 実行環境(OS/バージョン/実行コマンド)をREADMEに書いた
- 依存関係を固定した(lockfile or バージョン指定)
- 最小再現手順を残した(第三者が再現できることを確認)
- エラー時に原因が分かるログがある(握りつぶしていない)
- 入力のバリデーションがある(NULL/空/型違いで落ちない)
- 最低3ケースのテスト(正常/空/異常)がある
- 秘密情報(APIキー、顧客データ)をコード・ログ・プロンプトに入れていない
- 「動く」だけでなく、要件(期待する出力)を満たすことを確認した
まとめ:AIコードの正解は“当てる”ではなく“最短で検証して固定する”
ChatGPTのコードが動かないのは珍しくありません。原因の多くは、環境差・依存漏れ・存在しないAPI(幻覚)・仕様の曖昧さです。だからこそ、AIを「代筆者」にするより、叩き台→最小再現→切り分け→テストで固定のSOPで回すほうが、結果的に速く、納品品質も安定します。
次にやること(3ステップ)
- ステップ1:今ハマっているエラーを「再現手順・エラー全文・環境情報」で整理する(まずはメモでOK)
- ステップ2:最小再現(MRE)を作り、上のデバッグテンプレでAIに投げる
- ステップ3:直ったらテスト(正常/空/異常)を作って固定し、次の案件でも使える資産にする

