

この記事で分かること
自動化は「動けば勝ち」ではなく、実務では「壊さずに回り続ける」ことが価値です。副業初心者や社内効率化で失敗が怖い人ほど、最初に覚えるべきはツールの使い方ではなく、業務を壊さない設計(例外処理・ログ・再実行)です。
この記事では、次を手順書として解説します。
- 自動化が失敗しやすい理由(なぜ事故るのか)
- 壊さない設計の基本(権限・データ保護・冪等性)
- エラー処理・リトライの考え方(指数バックオフ、やっていい再試行/ダメな再試行)
- ログの取り方(最低限の項目、見返せる形、個人情報の注意)
- スケジューラ・監視・運用(止まる前提で回す)
結論:初心者の自動化は「小さく作り、止められ、戻せる」設計にすると安全です。
自動化で失敗しやすい理由(事故の典型パターン)
自動化が怖いのは正常です。なぜなら自動化は、人間がやれば気づくミス(違和感)を、無表情で高速に繰り返せるからです。つまり、ミスしたときの被害が大きくなりやすい。
初心者がやりがちな事故はだいたい次の5つです。ここが「自動化 失敗」の主戦場です。
- 二重実行:同じ処理が2回走って、二重登録・二重送信
- 一部だけ成功:途中で落ちて整合性が崩れる(例:Aは登録、Bは未登録)
- リトライ地獄:エラーで再試行を繰り返し、さらに被害が増える
- 権限事故:強すぎる権限で実行し、削除や上書きが発生
- ログなし:何が起きたか追えず、復旧できない
この「よくある事故」を、設計で先に潰すのがこの記事の目的です。
ポイント:自動化は“成功率”より“失敗時の被害”で評価されます。成功が9割でも、残り1割で業務が壊れたら負けです。
自動化を壊さない設計の全体像(最初に覚える7原則)
ツールは何でもいいです。ZapierでもGASでもPythonでも、守るべき原則は共通です。まずはこの7つを“チェックリスト”として覚えると迷いません。
- 原則1:最小権限(必要最低限の権限で動かす)
- 原則2:データ保護(個人情報・機密をログや外部に漏らさない)
- 原則3:冪等性(同じ処理を複数回実行しても結果が壊れない)
- 原則4:段階実行(いきなり本番を触らない。検証→小さく本番)
- 原則5:失敗前提(例外処理・リトライ・タイムアウト)
- 原則6:観測可能性(ログ・メトリクス・通知で状態が分かる)
- 原則7:止められる(スイッチ/一時停止/ロールバックの道を用意)
初心者ほど「全部作ってから運用」になりがちですが、逆です。運用を前提に小さく作ると、壊しにくくなります。
壊さないための最重要:権限とデータ保護
自動化で一番取り返しがつかないのは、データを壊すことと、漏らすことです。まずここを固めましょう。
最小権限(Least Privilege):強すぎる権限は事故の元
「動かないから権限を全部付ける」は、初心者がやりがちな危険行為です。たとえば、読み取りだけで良いのに書き込み権限を付けると、バグ1つで削除や上書きが起こりえます。
実務では次を徹底します。
- 閲覧だけならread-onlyにする
- 書き込みが必要でも、対象範囲を絞る(特定のフォルダ/シート/プロジェクト)
- APIトークンの権限(スコープ)は最小にする
- 個人アカウントではなく、可能なら専用の実行アカウントを用意する
データ保護:ログに個人情報を残さない
ログは重要ですが、何でも書いていいわけではありません。特に社内業務や顧客データを扱う場合、以下は原則ログに残さない(またはマスク)にします。
- 氏名・住所・電話番号・メールなどの個人情報
- APIキー・トークン・パスワード
- 決済情報、機密情報
どうしても識別が必要なら、IDだけを記録して、詳細は本体データ側で追えるようにします。
冪等性(べきとうせい):二重実行でも壊れない仕組み
自動化事故の王様が二重実行です。スケジューラが2回起動した、タイムアウトして再試行した、手動で再実行した…など、原因はいくらでも起こります。
冪等性とは「同じ処理を何回やっても結果が同じ(壊れない)」性質です。難しく聞こえますが、やることはシンプルです。
図解:冪等性のイメージ(スタンプ方式)
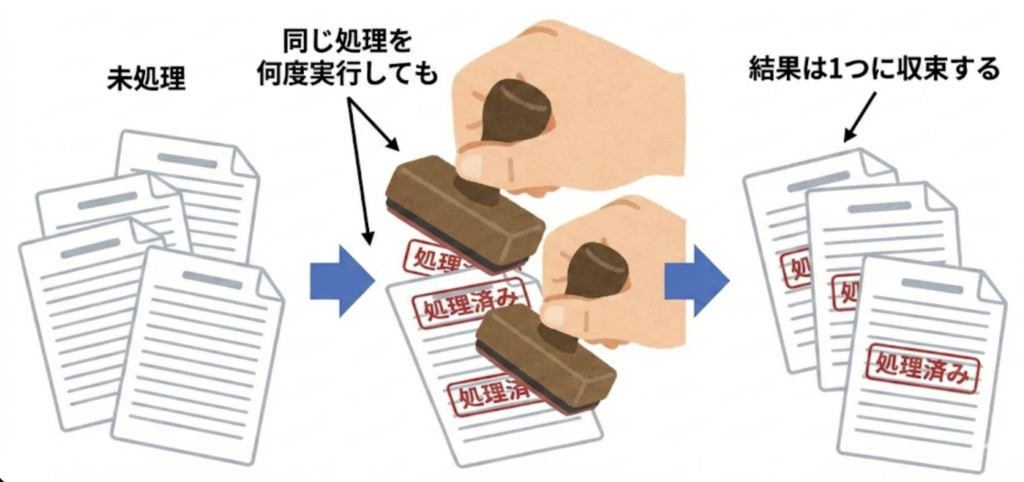
冪等性を作る3つの方法
- 方法1:一意キーで重複を防ぐ
例:注文ID、問い合わせID、メッセージIDなどを保存し、同じIDは処理しない - 方法2:処理済みフラグを持つ
例:スプレッドシートに「送信済み」列を作り、送信後にTRUEにする - 方法3:冪等キー(Idempotency Key)を使う
例:APIが対応している場合、同じキーでの重複作成を防げる
初心者はまず「一意キー」「処理済みフラグ」のどちらかを必ず入れる、と覚えるのが安全です。
エラー処理:例外は「握りつぶさない」
自動化のエラー処理は、根性ではなく設計です。重要なのは「失敗したときの行き先」を決めることです。
エラーの種類を3分類すると迷わない
- 一時的エラー(Transient):ネットワーク不安定、APIの一時障害、レート制限
- 恒久的エラー(Permanent):入力データ不正、権限不足、存在しないID
- 想定外(Bug):コードの例外、型ミス、NULLなど
基本方針:一時的だけリトライ、恒久的は止める
- 一時的エラー → 待って再試行(後述のリトライ)
- 恒久的エラー → そのデータだけ隔離して処理継続、または全体停止
- 想定外 → 即停止+通知(バグの可能性が高い)
「とりあえずtry/catchで握りつぶす」は最悪です。静かに失敗し続け、気づいたときに業務が壊れています。
リトライ設計:やっていい再試行/ダメな再試行
リトライは便利ですが、間違えると被害を増やします。初心者は次のルールでOKです。
やっていいリトライ(例)
- タイムアウト
- 一時的な5xx(相手側障害の可能性)
- レート制限に当たった(待てば回復する)
やってはいけないリトライ(例)
- 認証エラー(401)や権限不足(403)
- 入力データ不正(400系で内容が明確)
- すでに作成済みなのに「作成」を繰り返す(重複作成)
安全なリトライの型(指数バックオフ)
待ち時間を増やす再試行は指数バックオフ(Exponential Backoff)と呼ばれ、APIやネットワーク相手の標準的なやり方です。初心者はこの型に寄せると安全です。
- 回数に上限をつける(例:最大3回)
- 待ち時間を増やす(例:1秒→2秒→4秒)
- 冪等性(重複しても壊れない)をセットにする
図解:リトライロジックのフローチャート
「リトライ=連打」ではありません。落ち着いて待つ設計が正解です。
ログの取り方:最低限これだけ残せば復旧できる
ログは「動いてる証拠」ではなく、事故ったときに直せる情報です。初心者はまず、次の7項目をログに残せば十分です。
ログに残すべき最低限(7項目)
- 実行ID(この実行の固有番号)
- 開始時刻・終了時刻
- 処理対象(件数、対象IDの一覧 or 範囲)
- 処理結果(成功/失敗/スキップ)
- エラー内容(例外メッセージ、HTTPステータスなど)
- リトライ回数
- 実行者/環境(本番/検証、どのアカウントで動いたか)
ログの出し方:初心者におすすめの3段階
- 最初:スプレッドシートに1行ログ(手軽で見やすい)
- 慣れたら:ファイル/DBにJSONで保存(検索しやすい)
- 本格運用:ログ基盤+通知連携
副業や社内改善なら、まずは「見返せる」「共有できる」形式が正解です。スプレッドシートログは、非エンジニアとも共有しやすいので強いです。
ログに書かないもの(重要)
- APIキー・トークン・パスワード
- 個人情報(氏名、住所、電話番号など)
- 機密情報(顧客情報の全文など)
必要なら「IDのみ」や「マスク」へ。ログは便利な反面、漏れたら被害が大きいです。
再実行(リラン)の設計:止まっても“やり直せる”ことが正義
自動化は止まります。止まる前提で作ると強いです。ここで重要なのが再実行です。
再実行しやすい設計のコツ
- 1回の処理量を小さく(例:100件ずつ)
- 途中から再開できる(最後に処理したID/時刻を保存)
- スキップできる(処理済みフラグで飛ばせる)
- 二重実行に耐える(冪等性)
初心者の設計は「全部一気にやる」になりがちですが、それが一番危険です。小さく区切ると安全です。
スケジューラと監視:止まる前提で“気づける”仕組みを作る
自動化は「放置しても動く」が理想に見えますが、実際は放置すると壊れます。だから監視が必要です。
スケジューラ選びの考え方
- 社内の軽い自動化:GASのトリガー、Cron、Zapierなど
- 本番運用・重要業務:失敗通知や再実行が整った仕組みを選ぶ
何を使っても良いですが、「失敗時に気づけるか」が最重要です。
監視(通知)で最低限やるべきこと
- 失敗したら通知(メール/Slackなど)
- 成功しても要約を残す(件数、実行時間)
- 連続失敗は強いアラート(2回連続で失敗したら緊急、など)
「失敗したら気づける」ができるだけで、壊れにくさが段違いです。
具体例:問い合わせ→Slack通知→スプレッドシート記録(壊さない設計)
よくある自動化を1つ、壊さない設計に落とし込みます。
要件:問い合わせが来たらSlackに通知し、スプレッドシートにも保存する。失敗しても復旧できるようにしたい。
壊れないための設計(最低限)
- 一意キー:問い合わせIDを持つ(同じIDは二重処理しない)
- 処理済みフラグ:シートに「通知済み」「保存済み」列を作る
- 例外処理:Slackが失敗してもシート保存は行う(または逆)
- ログ:実行ID、対象ID、結果、エラー、リトライ回数を残す
- 通知:失敗時はSlack(別チャンネル)へアラート
落ちたときの復旧シナリオまで用意する
- Slack通知だけ失敗 → 「通知済み=false」の行だけ再実行
- シート保存だけ失敗 → 「保存済み=false」の行だけ再実行
- どっちも失敗 → 実行ログから対象IDを特定し、手動で再実行
この「落ちたときの道筋」があるだけで、怖さは大幅に減ります。
よくある失敗5選と回避策
失敗1:いきなり本番で動かしてデータを壊す
回避策:検証環境、テストデータ、少量実行(最初は10件だけ)を徹底します。「段階実行」が最強の安全策です。
失敗2:try/catchで握りつぶして“静かに失敗”する
回避策:失敗はログに残し、通知する。握りつぶさない。最低でも「失敗した件数」と「対象ID」が分かるようにします。
失敗3:リトライで二重登録・二重送信する
回避策:冪等性(処理済みフラグ・一意キー)を必ず入れる。リトライは回数制限と待ち時間増加をセットにします。
失敗4:権限を盛りすぎて事故る
回避策:最小権限。read-onlyから始め、必要になってから追加します。専用実行アカウントも強いです。
失敗5:ログがなくて原因も復旧もできない
回避策:実行ID、対象、結果、エラー、リトライを残す。個人情報やトークンは書かない。これだけで復旧力が上がります。
まとめ
自動化は「動けばOK」ではなく、実務では壊さずに回り続けることが価値です。副業初心者や社内効率化で失敗が怖い人ほど、ツールの前に設計を押さえると安全になります。
重要ポイントを整理します。
- 事故は「二重実行」「一部成功」「リトライ地獄」「権限事故」「ログなし」で起きる
- 壊さない7原則:最小権限、データ保護、冪等性、段階実行、失敗前提、観測可能性、止められる
- リトライは回数制限+待ち時間増加(指数バックオフ)+冪等性がセット
- ログは復旧のために取る。個人情報とトークンは残さない
- 再実行できる設計(小さく区切る・途中再開)が怖さを減らす
次にやること(3ステップ)
- ステップ1:自動化したい業務を1つ選び、「壊れたら困る点(データ/通知/権限)」を洗い出す
- ステップ2:冪等性(処理済みフラグ or 一意キー)とログ(7項目)をテンプレとして用意する
- ステップ3:少量データで段階実行し、失敗時の通知と再実行ルートがあることを確認してから本番へ

